
01
Use the Multimodal Context Pyramid
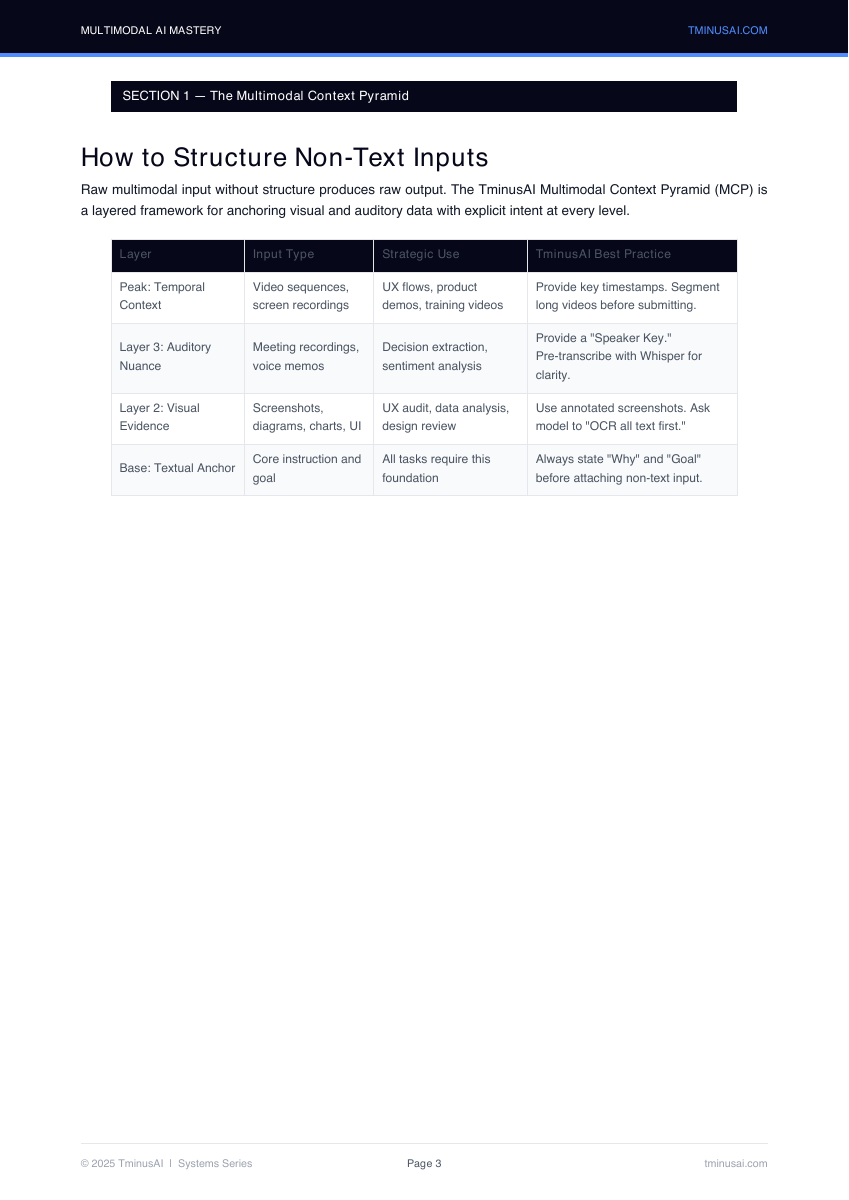
Introduces a layered model for grounding video, audio, screenshots, and documents with explicit goals before analysis begins.
- Anchor every multimodal task with a textual goal first
- Segment long videos and pre-transcribe multi-speaker audio before analysis

